此实验仅用于学习,禁止违法目的~
setoolkit,即社会工程学工具集Social-Engineer Toolkit,该工具可用来产生钓鱼网站,在kali上可直接使用,github上也有,下载链接 https://github.com/trustedsec/social-engineer-toolkit/set/。下面就是本次学习的记录了。
setoolkit,即社会工程学工具集Social-Engineer Toolkit,该工具可用来产生钓鱼网站,在kali上可直接使用,github上也有,下载链接 https://github.com/trustedsec/social-engineer-toolkit/set/。下面就是本次学习的记录了。
问题描述
Huffman树在编码中有着广泛的应用。在这里,我们只关心Huffman树的构造过程。
给出一列数{pi}={p0, p1, …, pn-1},用这列数构造Huffman树的过程如下:
1. 找到{pi}中最小的两个数,设为pa和pb,将pa和pb从{pi}中删除掉,然后将它们的和加入到{pi}中。这个过程的费用记为pa + pb。
2. 重复步骤1,直到{pi}中只剩下一个数。
在上面的操作过程中,把所有的费用相加,就得到了构造Huffman树的总费用。
本题任务:对于给定的一个数列,现在请你求出用该数列构造Huffman树的总费用。例如,对于数列{pi}={5, 3, 8, 2, 9},Huffman树的构造过程如下:
1. 找到{5, 3, 8, 2, 9}中最小的两个数,分别是2和3,从{pi}中删除它们并将和5加入,得到{5, 8, 9, 5},费用为5。
2. 找到{5, 8, 9, 5}中最小的两个数,分别是5和5,从{pi}中删除它们并将和10加入,得到{8, 9, 10},费用为10。
3. 找到{8, 9, 10}中最小的两个数,分别是8和9,从{pi}中删除它们并将和17加入,得到{10, 17},费用为17。
4. 找到{10, 17}中最小的两个数,分别是10和17,从{pi}中删除它们并将和27加入,得到{27},费用为27。
5. 现在,数列中只剩下一个数27,构造过程结束,总费用为5+10+17+27=59。 输入格式 输入的第一行包含一个正整数n(n<=100)。 接下来是n个正整数,表示p0, p1, …, pn-1,每个数不超过1000。
输出格式 输出用这些数构造Huffman树的总费用。 样例输入 5 5 3 8 2 9 样例输出 59
思路:
先将数组升序排序,a[0] 和 a[1]就是当前两个最小的数,然后a[0]+a[1]赋值给a[0],a[1]赋值为-1,总费用sum加上a[0] ,下一次排序后将这个数删除,依次循环,直到集合中元素只剩一个。
1 | |
问题描述
给定一个N阶矩阵A,输出A的M次幂(M是非负整数)
例如:
A =
1 2
3 4
A的2次幂
7 10
15 22
输入格式
第一行是一个正整数N、M(1<=N<=30, 0<=M<=5),表示矩阵A的阶数和要求的幂数
接下来N行,每行N个绝对值不超过10的非负整数,描述矩阵A的值
输出格式
输出共N行,每行N个整数,表示A的M次幂所对应的矩阵。相邻的数之间用一个空格隔开
样例输入
2 2
1 2
3 4
样例输出
7 10
15 22
–这个题其实不难,就是一开始我忘了矩阵乘法的相关知识Orz(⊙﹏⊙)
要注意分类讨论,矩阵的0次幂是单位矩阵,1次幂是矩阵本身,2+次幂就要借用另外两个数组来计算了。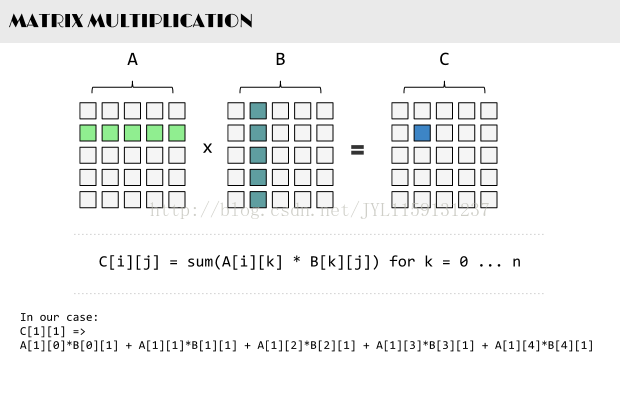
AC代码:
1 | |
一定要注意当m=0和m=1时,要注意结束程序,不然会出错。
例如,输入10 0:
去年华为云服务器做活动,白嫖了一个弹性云服务器,一直没有用,今天着手来配置一下,不然要过期了。一边配置一边记录流程,亲测有效哦!
问题描述
FJ在沙盘上写了这样一些字符串:
A1 = “A”
A2 = “ABA”
A3 = “ABACABA”
A4 = “ABACABADABACABA”
… …
你能找出其中的规律并写所有的数列AN吗?
输入格式
仅有一个数:N ≤ 26。
输出格式
请输出相应的字符串AN,以一个换行符结束。输出中不得含有多余的空格或换行、回车符。
样例输入
3
样例输出
ABACABA
1 | |
问题描述
回文串,是一种特殊的字符串,它从左往右读和从右往左读是一样的。小龙龙认为回文串才是完美的。现在给你一个串,它不一定是回文的,请你计算最少的交换次数使得该串变成一个完美的回文串。
交换的定义是:交换两个相邻的字符
例如mamad
第一次交换 ad : mamda
第二次交换 md : madma
第三次交换 ma : madam (回文!完美!)
输入格式
第一行是一个整数N,表示接下来的字符串的长度(N <= 8000)
第二行是一个字符串,长度为N.只包含小写字母
输出格式
如果可能,输出最少的交换次数。
否则输出Impossible
样例输入
5
mamad
样例输出
3
思路:
贪心法,从左边起依次扫描,每记录一个字母,就寻找从右边起最近的与它相同的字母,移动到回文的位置,记录步数,如果最近的与它相同的字母是它本身,说明它在字串里单独存在,可以根据单独存在的字母的个数以及字串的长度来判断impossible的情况,如果排除impossible的情况,则记录它到字串中间的步数,并不需要移动它。
其中有两个注意点:
1 | |
问题描述
Tom教授正在给研究生讲授一门关于基因的课程,有一件事情让他颇为头疼:一条染色体上有成千上万个碱基对,它们从0开始编号,到几百万,几千万,甚至上亿。
比如说,在对学生讲解第1234567009号位置上的碱基时,光看着数字是很难准确的念出来的。
所以,他迫切地需要一个系统,然后当他输入12 3456 7009时,会给出相应的念法:
十二亿三千四百五十六万七千零九
用汉语拼音表示为
shi er yi san qian si bai wu shi liu wan qi qian ling jiu
这样他只需要照着念就可以了。
你的任务是帮他设计这样一个系统:给定一个阿拉伯数字串,你帮他按照中文读写的规范转为汉语拼音字串,相邻的两个音节用一个空格符格开。
注意必须严格按照规范,比如说“10010”读作“yi wan ling yi shi”而不是“yi wan ling shi”,“100000”读作“shi wan”而不是“yi shi wan”,“2000”读作“er qian”而不是“liang qian”。
输入格式
有一个数字串,数值大小不超过2,000,000,000。
输出格式
是一个由小写英文字母,逗号和空格组成的字符串,表示该数的英文读法。
样例输入
1234567009
样例输出
shi er yi san qian si bai wu shi liu wan qi qian ling jiu
思路:
AC代码:
1 | |
总的来说,这题还是比较坑的orz
参考自https://blog.csdn.net/qq_40691051/article/details/105001465
话说这个世界上有各种各样的兔子和乌龟,但是研究发现,所有的兔子和乌龟都有一个共同的特点——喜欢赛跑。于是世界上各个角落都不断在发生着乌龟和兔子的比赛,小华对此很感兴趣,于是决定研究不同兔子和乌龟的赛跑。
问题描述
有n(2≤n≤20)块芯片,有好有坏,已知好芯片比坏芯片多。
每个芯片都能用来测试其他芯片。用好芯片测试其他芯片时,能正确给出被测试芯片是好还是坏。而用坏芯片测试其他芯片时,会随机给出好或是坏的测试结果(即此结果与被测试芯片实际的好坏无关)。
给出所有芯片的测试结果,问哪些芯片是好芯片。
输入格式
输入数据第一行为一个整数n,表示芯片个数。
第二行到第n+1行为n*n的一张表,每行n个数据。表中的每个数据为0或1,在这n行中的第i行第j列(1≤i, j≤n)的数据表示用第i块芯片测试第j块芯片时得到的测试结果,1表示好,0表示坏,i=j时一律为1(并不表示该芯片对本身的测试结果。芯片不能对本身进行测试)。
输出格式
按从小到大的顺序输出所有好芯片的编号
样例输入
3
1 0 1
0 1 0
1 0 1
样例输出
1 3
思路:
刚看到这道题是没有思路的,想着假设1号芯片是好的再一一比对,有点麻烦。后来在网上搜,发现简便方法,利用离散中的抽屉原理(还没学过)。
抽屉原理:如果把n+1个物体放入n个抽屉里,则必有一个抽屉里至少放了两个物体。
在这道题中的应用就是假如有n/2个芯片说某一个芯片是好的的话,那该芯片就是好的。
1 | |